

L’objectif de ce groupe de travail était de monter en compétences sur l’utilisation de Docker en mode swarm.
Swarm est un mode natif de Docker depuis la version 1.13. Il permet d’utiliser un groupe de machines exécutant Docker comme un seul Docker Engine. On parlera de grappe ou de cluster.
Les commandes sont exécutées sur le cluster à l’aide d’un swarm manager.
Les machines (physiques ou virtuelles) sont désignées comme des nœuds (nodes).
- Les machines swarm managers :
- sont les seules du cluster à pouvoir exécuter les commandes ;
- autorisent d’autres machines à se joindre au cluster.
- Les machines swarm workers :
- sont utiles uniquement pour augmenter la capacité du cluster.
Source : https://docs.docker.com/engine/swarm/
EOLE, Zéphir, Docker et le mode swarm
L’application Zéphir en cours de développement utilise Docker : https://dev-eole.ac-dijon.fr/projects/zephir/
Il est convenu que les services développés dans cette application puissent fonctionner en mode multi-instances : https://dev-eole.ac-dijon.fr/doc/zephir/
Objectifs à atteindre :
- initialiser un cluster swarm ;
- construire l’application dans le fichier docker-compose ;
- lancer l’application sur un seul nœud ;
- intégrer des nœuds dans le cluster ;
- tester la scalabilité du cluster ;
- tester la résilience de l’application.
Installation d’un cluster docker en mode swarm
Par facilité il a été décidé de partir d’une machine virtuelle disponible sur notre infrastructure de développement utilisée pour le développement de l’application Zéphir, cependant il est tout à fait possible de partir d’une distribution GNU/Linux et d’installer Docker.
Le code source de l’atelier est disponible sur Github : https://github.com/gwen21/swarm.git
Pré-requis
Il faut disposer de plusieurs machines Docker engine.
Les ports suivants doivent être accessibles entre chaque machine :
- TCP/2377 pour les communications de gestion du cluster
- TCP/7946 et UDP/7946 pour les communications entre les nœuds
- UDP/4789 pour le trafic réseau
Initialisation du cluster sur la première machine
Cloner le dépôt : git clone https://github.com/gwen21/swarm.git && cd swarm
Initialiser le cluster sur une première machine virtuelle : docker swarm init
La machine devient swarm manager.
Construire les images Docker sans démarrer les conteneurs : docker-compose up --build --no-start
Joindre des nouveaux nœuds
Pour un nœud worker, la commande suivante depuis un manager indique la commande à exécuter sur le nouveau nœud pour qu’il devienne worker du cluster : docker swarm join-token worker
Pour un nœud manager, la commande suivante depuis un manager indique la commande à exécuter sur le nouveau nœud pour qu’il devienne manager du cluster : docker swarm join-token manager
Ajouter 2 nœuds worker sur une deuxième et une troisième image virtuelle.
Visualiser
Depuis le nœud manager, lister les nœuds du cluster : docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
iheocb4wo1vdfind2psz3w33n * node200 Ready Active Leader
b8jqub7lgcvpsjebeytjmztwf node201 Ready Active
qmxn8ly9okf0zzuui3j202ejq node202 Ready Active
Déployer l’application, dans le dépôt cloné depuis le nœud manager : docker stack deploy -c docker-compose.yml hackathon
Les services sont déployés sur le cluster, visualiser l’état du cluster :
- depuis le nœud manager :
docker stack ps hackathon
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
2oc7huepviko hackathon_minio.1 minio/minio:latest node202 Running Starting 3 seconds ago
eyukkhagv1ri hackathon_consul.1 consul:0.9.3 node201 Running Running 9 seconds ago
7aramnxhlqd6 hackathon_swarm_visualizer.1 dockersamples/visualizer:latest node200 Running Preparing 14 seconds ago
imlxeye2zd6l hackathon_minio.2 minio/minio:latest node201 Running Starting 3 seconds ago
ngjferp2m77v hackathon_minio.3 minio/minio:latest node202 Running Starting 3 seconds ago
- depuis un navigateur :
http://<IP_manager1>:8080- Le service
hackathon_swarm_visualizerest sur le manager - Les 3 instances du service
hackathon_miniosont réparties sur les 2 workers
- Le service

Scalabilité des services
Scaler le service hackathon_minio : docker service scale hackathon_minio=10
hackathon_minio scaled to 10
overall progress: 10 out of 10 tasks
1/10: running [==================================================>]
2/10: running [==================================================>]
3/10: running [==================================================>]
4/10: running [==================================================>]
5/10: running [==================================================>]
6/10: running [==================================================>]
7/10: running [==================================================>]
8/10: running [==================================================>]
9/10: running [==================================================>]
10/10: running [==================================================>]
verify: Service converged
- depuis un navigateur :
http://<IP_manager1>:8080
Les 10 instances du service minio sont réparties sur les 2 workers.
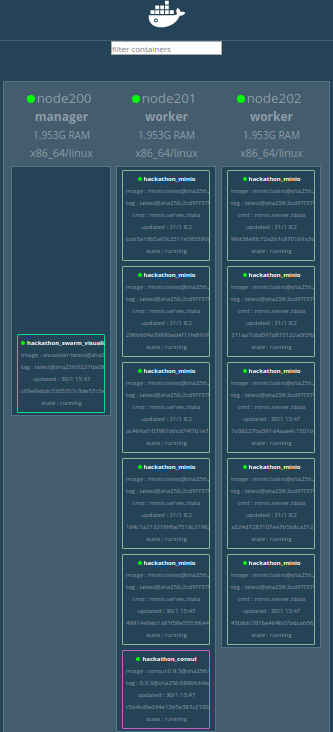
Modifier le fichier docker-conpose.yml pour pérenniser les 10 instances du service hackathon_minio : sed -i 's/replicas:.*$/replicas: 10/' docker-compose.yml
Augmenter la capacité du cluster en ajoutant un worker et visualiser le cluster :
- déployer une machine virtuelle et lancer la commande permettant de joindre un nouveau worker

- actualiser le cluster :
docker stack deploy -c docker-compose.yml hackathon
hackathon_minio
overall progress: 10 out of 10 tasks
1/10: running [==================================================>]
2/10: running [==================================================>]
3/10: running [==================================================>]
4/10: running [==================================================>]
5/10: running [==================================================>]
6/10: running [==================================================>]
7/10: running [==================================================>]
8/10: running [==================================================>]
9/10: running [==================================================>]
10/10: running [==================================================>]
verify: Service converged
- depuis un navigateur :
http://<IP_manager1>:8080

Les 10 instances du service hackathon_minio sont réparties sur les 3 workers.
Changement du rôle d’un nœud
Passer un nœud worker en manager et visualiser le cluster :
- depuis le nœud manager :
docker node promote <worker1> - depuis un navigateur :
http://<IP_manager1>:8080
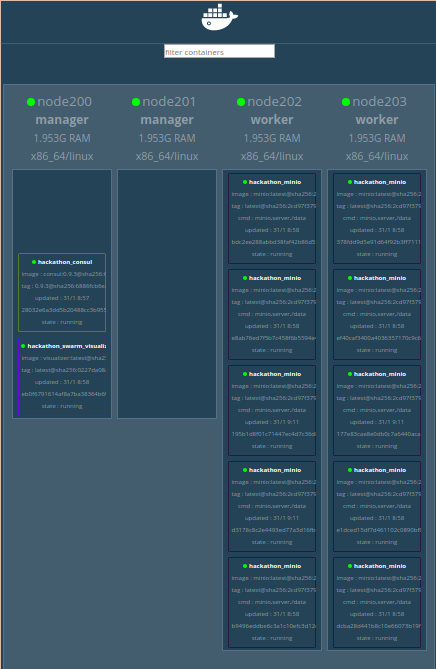
Les 10 instances du service hackathon_minio sont réparties sur les 2 workers.
Passer le premier nœud manager en worker et visualiser le cluster :
- cloner le dépôt depuis le deuxième nœud manager
git clone https://github.com/gwen21/swarm.git && cd swarm
- indiquer 10 instances du service
hackathon_minio*sed -i 's/replicas:.*$/replicas: 10/' docker-compose.yml
- depuis le deuxième nœud manager :
docker node demote <manager1> - actualiser le cluster depuis le deuxième nœud manager
docker stack deploy -c docker-compose.yml hackathon
- depuis un navigateur :
http://<IP_manager2>:8080

Le premier nœud est passé en worker , le service hackathon_visualizer passe sur le nouveau nœud manager et les 10 instances du service hackathon_minio sont réparties sur les 3 workers.
Augmenter le nombre d’instance du service hackathon_minio :
- depuis le deuxième nœud manager :
docker service scale hackathon_minio=15 - depuis un navigateur :
http://<IP_manager2>:8080
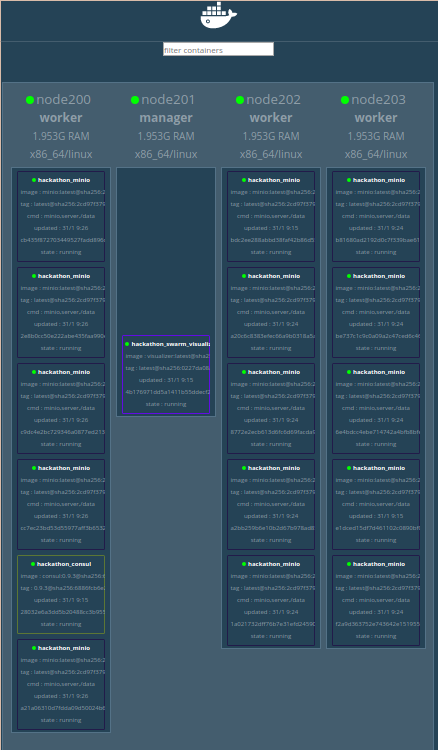
Les 15 instances du service hackathon_minio sont réparties sur les 3 workers
Tester la résilience du cluster
Tuer sauvagement le dernier nœud worker (<worker3>) et visualiser le cluster :
- depuis un navigateur :
http://<IP_manager2>:8080
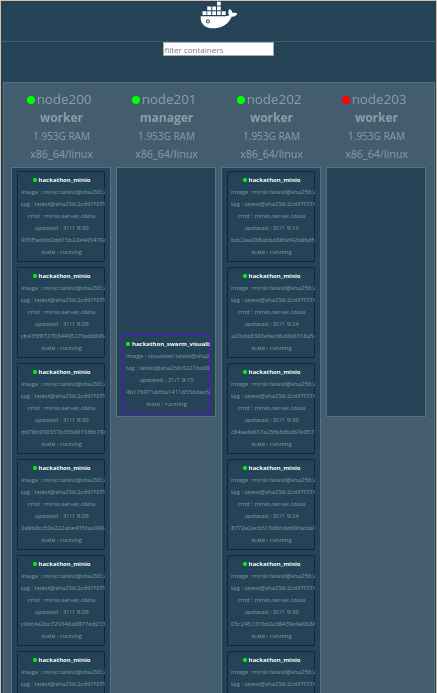
Le worker tué passe au rouge et les 15 instances du service hackathon_minio sont réparties sur les 2 workers restants.
Supprimer le nœud tué du cluster et visualiser le cluster :
- depuis le deuxième manager :
docker node rm <worker3> - depuis un navigateur :
http://<IP_manager2>:8080
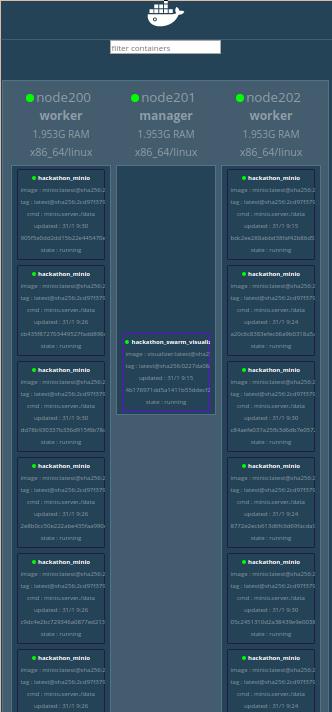
Le troisième worker disparaît.
Conclusion
Nous avons pu exploiter rapidement Docker en mode swarm. Plusieurs machines peuvent être pilotées par Docker. Ce travail peut servir de base au développement de Zéphir. Cependant le passage en mode swarm sur cette application nécessiterait quelques adaptations :
- par défaut, Docker tourne en mode single-host, les conteneurs ne sont déployés que sur la machine hôte ;
- la syntaxe du fichier de configuration docker-compose doit passer à 3.2 ;
- les conteneurs doivent être construits à l’avance avec docker-compose sans lancer l’application ;
- le fichier de configuration docker-compose devra décrire le mode et les contraintes de déploiement ;
- le lancement de l’application se fait avec docker stack une fois les conteneurs construits.